When we’re hit with high-volume data in Go, we usually reach for the standard worker pool. It’s reliable, it’s fast, and it works—until the order of execution actually matters.
The moment “order” is mentioned, I see a lot of teams start over-engineering their cloud setup. They begin partitioning queues at the infrastructure level, spinning up dedicated consumer pools for every partition, and adding massive complexity to their monitoring and deployment pipelines.
All of that adds up - both in your cloud bill and your cognitive load.
My take? Start at the application level. Unless you’re processing millions of messages per second, a Sharded Worker Pool in Go is often all you need. You get the sequential integrity of a single-threaded process with the throughput of a parallel system.
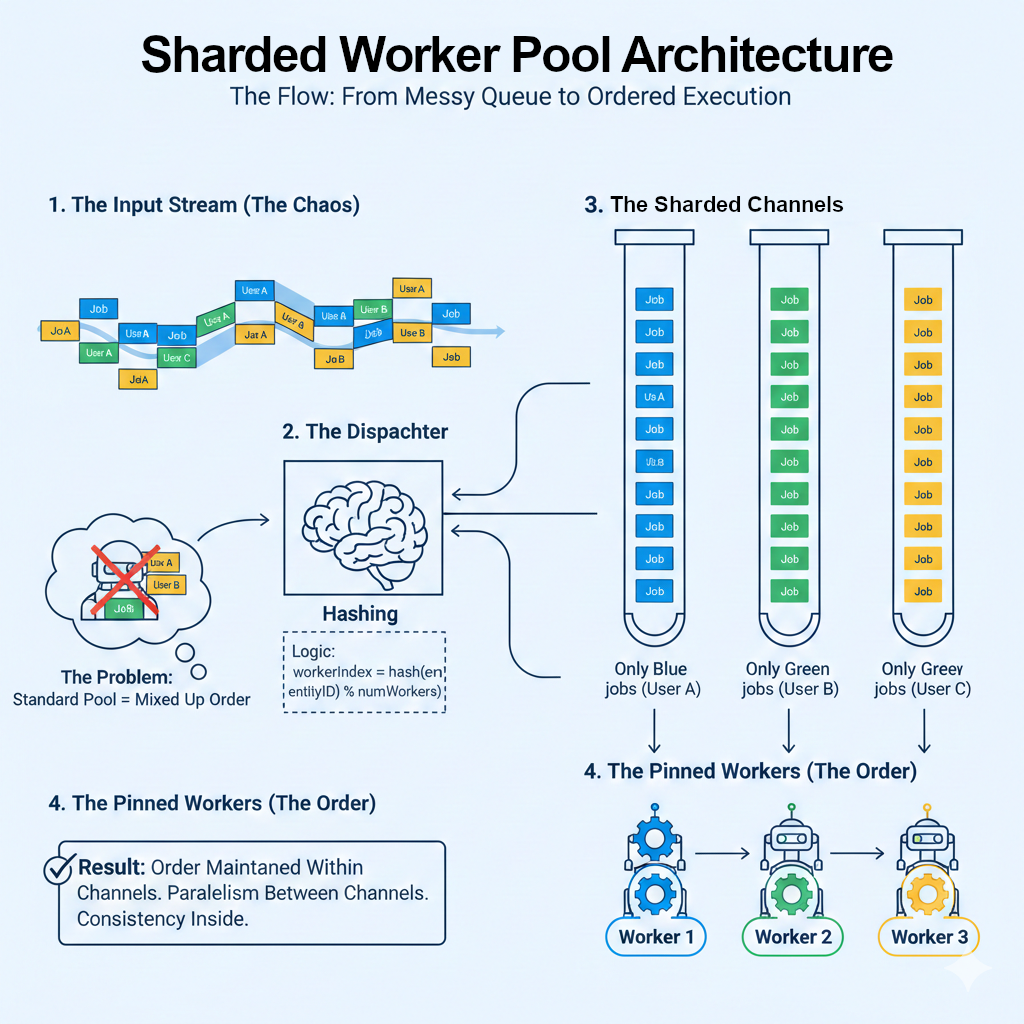
The Problem: The “Order-Blind” Worker Pool In a standard worker pool, you have a set of workers listening on a single channel. If Job #1 (Create) and Job #2 (Update) are sent in sequence, there is no guarantee Job #1 finishes first. If a worker hits a GC pause, your data integrity is compromised.
|
|
The Solution: The Sharded Pattern
By sharding on deviceId and having separate channels per worker, we route all jobs for a specific entity (like a deviceId) to the same worker. This ensures that for any given device, their tasks are handled sequentially, while the system as a whole remains parallel.
|
|
Case Study: Preventing “Ghost Alerts” in IoT
In industrial monitoring, sequence is a safety requirement. Imagine a fleet of industrial chillers. You receive two events from Chiller_77:
Event A: Internal_Temp: 110°C (Critical Threshold)
Event B: Status: Emergency_Shutdown
In a standard pool, Worker 2 might process the Shutdown before Worker 1 finishes processing the Alert. Your dashboard triggers a critical overheat alarm for a machine that is already off. By sharding on device_id, Event A is always processed before Event B. You eliminate “ghost alerts” without adding a single line of infrastructure.
Why This Matters for Senior Engineers
Sequential Integrity by Design: You get a single-threaded execution model for the individual entity, with massive parallelism for the fleet.
Lean Infrastructure: You avoid the “Infra-first” trap. No complex queue partitioning or extra app servers required.
Mechanical Sympathy: Data for specific IDs stays local to specific goroutines, which is better for cache locality and predictable memory usage.
The Trade-off: The “Hot Shard”
As seniors, we know there are no silver bullets. If one user_id accounts for 80% of your traffic, that worker will bottleneck. However, for the vast majority of SaaS and IoT use cases, the peace of mind that comes with guaranteed sequence far outweighs the risk of a slightly unbalanced load.
Don’t just scale your infra. Refine your patterns.