Quando veniamo colpiti da dati ad alto volume in Go, di solito ricorriamo al classico pool di worker. È affidabile, veloce e funziona… fino a quando l’ordine di esecuzione non conta davvero.
Il momento in cui si menziona “l’ordine”, vedo molti team iniziare a sovra-ingegnerizzare la propria configurazione cloud. Iniziano a partizionare le code a livello di infrastruttura, avviando pool di consumatori dedicati per ogni partizione e aggiungendo una massiccia complessità alle loro pipeline di monitoraggio e distribuzione.
Tutto questo si somma: sia nella bolletta del cloud che nel carico cognitivo.
La mia opinione? Inizia a livello applicativo. A meno che tu non stia elaborando milioni di messaggi al secondo, uno Sharded Worker Pool (pool di worker suddivisi) in Go è spesso tutto ciò di cui hai bisogno. Ottieni l’integrità sequenziale di un processo single-thread con il throughput di un sistema parallelo.
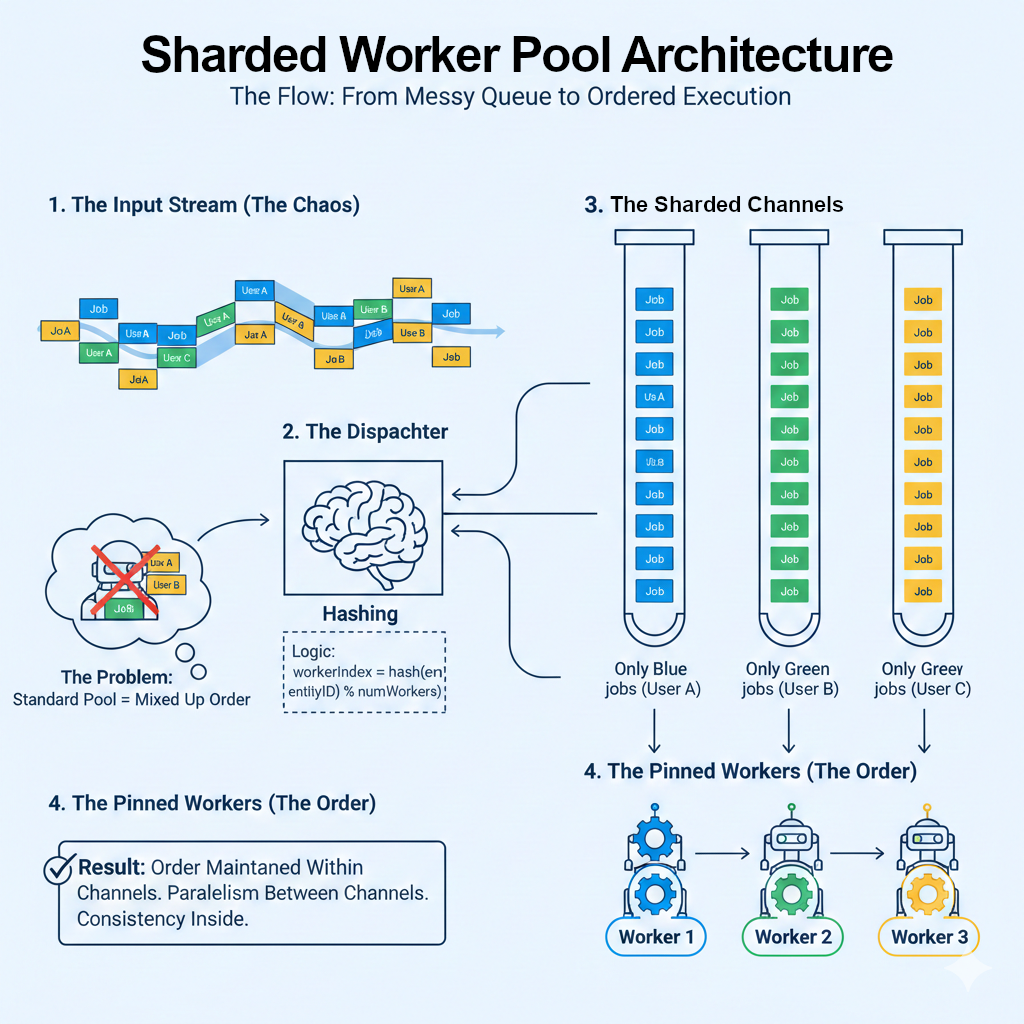
Il Problema: Il Pool di Worker “Cieco all’Ordine” In uno standard worker pool, hai un set di worker in ascolto su un singolo canale. Se il Job #1 (Creazione) e il Job #2 (Aggiornamento) vengono inviati in sequenza, non c’è garanzia che il Job #1 finisca per primo. Se un worker incontra una pausa della Garbage Collection, l’integrità dei tuoi dati è compromessa.
|
|
La Soluzione: Il Pattern Sharded
Effettuando lo sharding sul deviceId (o ID entità) e avendo canali separati per ogni worker, instradano tutti i job per un’entità specifica allo stesso worker. Questo garantisce che per qualsiasi dispositivo, i suoi task vengano gestiti in modo sequenziale, mentre il sistema nel suo complesso rimane parallelo.
|
|
Caso di Studio: Prevenire gli “Allarmi Fantasma” nell’IoT
Nel monitoraggio industriale, la sequenza è un requisito di sicurezza. Immagina una flotta di refrigeratori industriali. Ricevi due eventi dal Chiller_77:
Evento A: Internal_Temp: 110°C (Soglia Critica)
Evento B: Status: Emergency_Shutdown (Spegnimento d’Emergenza)
In un pool standard, il Worker 2 potrebbe elaborare lo spegnimento prima che il Worker 1 finisca di elaborare l’allarme. La tua dashboard innesca un allarme critico di surriscaldamento per una macchina che è già spenta. Effettuando lo sharding sul device_id, l’Evento A viene sempre elaborato prima dell’Evento B. Elimini gli “allarmi fantasma” senza aggiungere una singola riga di infrastruttura.
Perché Questo è Importante per i Senior Engineer
Integrità Sequenziale by Design: Ottieni un modello di esecuzione a thread singolo per la singola entità, con massiccio parallelismo per l’intera flotta.
Infrastruttura Snella: Eviti la trappola dell’“Infrastruttura prima di tutto”. Nessun complesso partizionamento della coda o extra server applicativi richiesti.
Simpatia Meccanica: I dati per gli ID specifici rimangono locali alle specifiche goroutine, il che è meglio per la località della cache e un uso prevedibile della memoria.
Il Compromesso: L’“Hot Shard”
Come senior, sappiamo che non ci sono soluzioni magiche. Se un user_id rappresenta l'80% del tuo traffico, quel worker diventerà un collo di bottiglia. Tuttavia, per la stragrande maggioranza dei casi d’uso SaaS e IoT, la tranquillità derivante dalla sequenza garantita supera di gran lunga il rischio di un carico leggermente sbilanciato.
Non limitarti a scalare la tua infrastruttura. Perfeziona i tuoi pattern.